
背景(可以不看)
实验室项目开发的APP需要有语音提示功能,之前的做法是人工录音,剪辑片段,调用Android的多媒体,播放,呵呵呵,,,这是21世纪!这样肯定显得有点low啊,且不说档次,应用场景也不足啊,人工录音内容固定,这不适合我们的需求。其实我当时也不知道这技术叫语音合成,老师提了一提,下来一百度,科大讯飞果断站了出来,提供了API,给你点个赞!这里介绍一下如何使用该API中的语音合成技术。
准备工作
注册开发者APPID
首先需要做的就是注册能够使用该API的APPID,如今使用这种API都需要注册,比如百度地图API等,不想多说,并向你抛出了个链接 http://www.xfyun.cn
导入SDK
注册完APPDID之后,下载开发包,解压缩,得到如下文件,在Android Studio项目结构下的app下新建libs,将其中的文件全部copy到libs下,如下图所示:
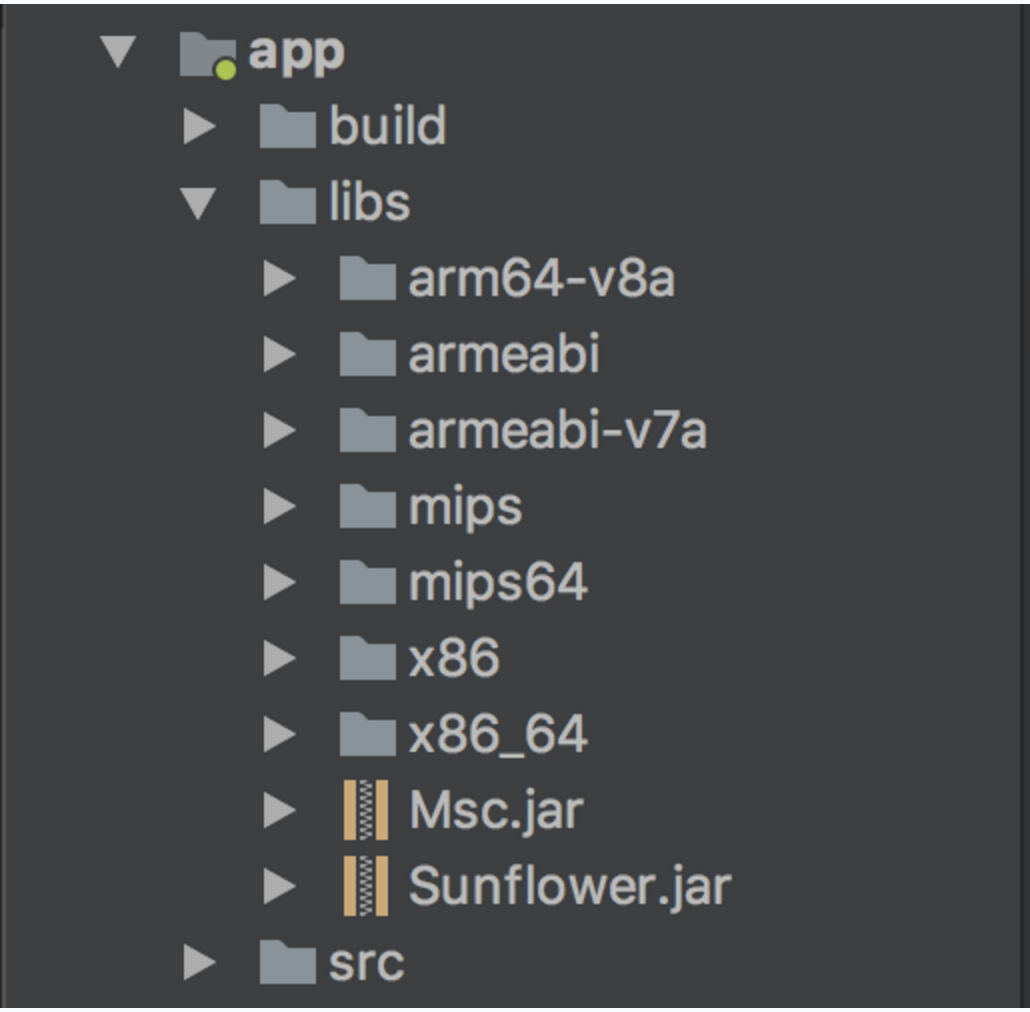
这里要注意啊,导进来要进行Gradle的编译啊,并且注意到每一项前面的三角符号是可以点开的,下面有内容的,这是需要编译之后才有,如果不能打开,相当于只是添加了些文件,后面使用里面的类,代码无法自动提示,MB,都没编译进来,有个屁啊,(本人踩过的坑,手动捂脸)
添加用户权限
需要配置如下权限1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25<!--连接网络权限,用于执行云端语音能力 -->
<uses-permission android:name="android.permission.INTERNET"/>
<!--获取手机录音机使用权限,听写、识别、语义理解需要用到此权限 -->
<uses-permission android:name="android.permission.RECORD_AUDIO"/>
<!--读取网络信息状态 -->
<uses-permission android:name="android.permission.ACCESS_NETWORK_STATE"/>
<!--获取当前wifi状态 -->
<uses-permission android:name="android.permission.ACCESS_WIFI_STATE"/>
<!--允许程序改变网络连接状态 -->
<uses-permission android:name="android.permission.CHANGE_NETWORK_STATE"/>
<!--读取手机信息权限 -->
<uses-permission android:name="android.permission.READ_PHONE_STATE"/>
<!--读取联系人权限,上传联系人需要用到此权限 -->
<uses-permission android:name="android.permission.READ_CONTACTS"/>
<!--外存储写权限,构建语法需要用到此权限 -->
<uses-permission android:name="android.permission.WRITE_EXTERNAL_STORAGE"/>
<!--外存储读权限,构建语法需要用到此权限 -->
<uses-permission android:name="android.permission.READ_EXTERNAL_STORAGE"/>
<!--配置权限,用来记录应用配置信息 -->
<uses-permission android:name="android.permission.WRITE_SETTINGS"/>
<!--手机定位信息,用来为语义等功能提供定位,提供更精准的服务-->
<!--定位信息是敏感信息,可通过Setting.setLocationEnable(false)关闭定位请求 -->
<uses-permission android:name="android.permission.ACCESS_FINE_LOCATION"/>
<!--如需使用人脸识别,还要添加:摄相头权限,拍照需要用到 -->
<uses-permission android:name="android.permission.CAMERA" />
配置Gradle
使用AS开发Android Application Gradle的配置少不了,官方的文档上没有指出需要配置Gradle,但是事实证明不配置的话,会出现一个很奇怪的异常,在Module下的build.gradle文件:
- 在
defaultConfig下添加以下内容:1
2
3
4
5
6
7// 配置.so文件
ndk {
// 选择要添加的对应的cpu类型的.so库
abiFilters 'x86', 'armeabi', 'armeabi-v7a', 'armeabi-v8a', 'mips','mips64','x86_64'
}
```
2. 在`buildTypes`下添加以下内容:
//配置JNILibs
sourceSets {
main {
jniLibs.srcDirs = [‘libs’]
}
}1
2
3
4
5###
到这里,准备工作应该是准备完成了
### 干正事
#### SDK的初始化
初始化就一句话
// 进行SDK的初始化
SpeechUtility.createUtility(APP.this, SpeechConstant.APPID + “=yourAPPID”);1
2
3
4
5
6
7
8
9
10这句话一般写在app初始化时,如果你是写demo,只有一个Activity,那么就写在onCreate之后就可以,但是我相信,真正使用绝非这么简单,所以配置到APP文件中最好,我一开始不知道什么是APP文件(手动捂脸,好low),其实APP文件是一个java类文件,继承Application,如下图:

Application这个类,一看就应该明了,是我们每个应用程序都用的,然后如何将我们新建的APP和我们的Android程序关联,看下图:

这是`AndroidManifest.xml` 下的配置项,将这里的application指定为我们自己创建的java类文件即可,看到`.APP`前面的那一个`.`点没有,表示路径,说明我们的APP.java类直接在我们的包名下。如下图:

这里`com.jiajia.speechdemo`就是我的包名。
#### 封装语音合成工具类
在上面的截图中有一个TTSUtility类,没错,我们把语音合成疯转在一个工具类中。同时将其打造成单例模式。这样在我们整个应用程序中,只有一个工具类,就不用每次需要合成是都new一个对象
public class TTSUtility {
// 发音人
public final static String[] COLOUD_VOICERS_VALUE = {“xiaoyan”, “xiaoyu”, “catherine”, “henry”, “vimary”, “vixy”, “xiaoqi”, “vixf”, “xiaomei”,”xiaolin”, “xiaorong”, “xiaoqian”, “xiaokun”, “xiaoqiang”, “vixying”, “xiaoxin”, “nannan”, “vils”,};
private static final String TAG = "TTSUtility";
// 语音合成对象
private static SpeechSynthesizer mTts;
//上下文
private Context mContext;
private volatile static TTSUtility instance;
/**
* 合成回掉监听
*/
private static SynthesizerListener mTtsListener = new SynthesizerListener() {
@Override
public void onSpeakBegin() {
Log.d(TAG, "开始播放");
}
@Override
public void onBufferProgress(int percent, int beginPos, int endPos, String info) {
// TODO 缓冲的进度
Log.d(TAG, "缓冲 : " + percent);
}
@Override
public void onSpeakPaused() {
Log.d(TAG, "暂停播放");
}
@Override
public void onSpeakResumed() {
Log.d(TAG, "继续播放");
}
@Override
public void onSpeakProgress(int percent, int beginPos, int endPos) {
// TODO 说话的进度
Log.d(TAG, "合成 : " + percent);
}
@Override
public void onCompleted(SpeechError error) {
if (error == null) {
Log.d(TAG, "播放完成");
} else if (error != null) {
Log.d(TAG, error.getPlainDescription(true));
}
}
@Override
public void onEvent(int eventType, int arg1, int arg2, Bundle obj) {
}
};
/**
* 构造方法
*
* @param context 上下文
*/
private TTSUtility(Context context) {
mContext = context;
// 初始化合成对象
mTts = SpeechSynthesizer.createSynthesizer(mContext, new InitListener() {
@Override
public void onInit(int code) {
if (code != ErrorCode.SUCCESS) {
Log.d("fjj", "初始化失败,错误码:" + code);
}
Log.d("fjj", "初始化失败,q错误码:" + code);
}
});
}
public static TTSUtility getInstance(Context context) {
if (instance == null) {
synchronized (TTSUtility.class) {
if (instance == null) {
instance = new TTSUtility(context);
}
}
}
return instance;
}
/**
* 停止语音播报
*/
public static void stopSpeaking() {
// 对象非空并且正在说话
if (null != mTts && mTts.isSpeaking()) {
// 停止说话
mTts.stopSpeaking();
}
}
/**
* 判断当前有没有说话
*
* @return
*/
public static boolean isSpeaking() {
if (null != mTts) {
return mTts.isSpeaking();
} else {
return false;
}
}
/**
* 开始合成
*
* @param text
*/
public void speaking(String text) {
if (TextUtils.isEmpty(text))
return;
int code = mTts.startSpeaking(text, mTtsListener);
Log.d("fjj", "-----" + code + "++++++++++");
if (code != ErrorCode.SUCCESS) {
if (code == ErrorCode.ERROR_COMPONENT_NOT_INSTALLED) {
Toast.makeText(mContext, "没有安装语音+ code = " + code, Toast.LENGTH_SHORT).show();
} else {
Toast.makeText(mContext, "语音合成失败,错误码: " + code, Toast.LENGTH_SHORT).show();
}
}
}
/**
* 参数设置
*
* @return
*/
private void setParam() {
// 清空参数
mTts.setParameter(SpeechConstant.PARAMS, null);
// 引擎类型 网络
mTts.setParameter(SpeechConstant.ENGINE_TYPE, SpeechConstant.TYPE_CLOUD);
// 设置发音人
mTts.setParameter(SpeechConstant.VOICE_NAME, COLOUD_VOICERS_VALUE[0]);
// 设置语速
mTts.setParameter(SpeechConstant.SPEED, "50");
// 设置音调
mTts.setParameter(SpeechConstant.PITCH, "50");
// 设置音量
mTts.setParameter(SpeechConstant.VOLUME, "100");
// 设置播放器音频流类型
mTts.setParameter(SpeechConstant.STREAM_TYPE, "3");
// mTts.setParameter(SpeechConstant.TTS_AUDIO_PATH, Environment.getExternalStorageDirectory() + "/KRobot/wavaudio.pcm");
// 背景音乐 1有 0 无
// mTts.setParameter("bgs", "1");
}
}1
2
这样封装之后在任何你想要"说话"的地方直接调用下面者句话就可以;
TTSUtility.getInstance(getApplicationContext()).speaking(“编程使我快乐”);`
可以看到封装的工具类中可以进行参数的设置,主要包括以下内容:
语言(LANGUAGE,中文、英文等)
方言(ACCENT,中文的普通话,粤语等)
发音人特征(性别,年龄,语气)
语速(SPEED)
音量(VOLUME)
语调(PITCH)
音频采样率(SAMPLE_RATE)
感兴趣可以自己多尝试!
本人菜鸟程序猿一枚,如有错误,请指出,Thanks!
参考资料
最后
此致,敬礼

